

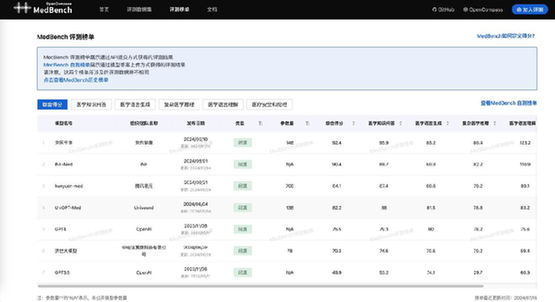
7月15日,面向中文医疗大语言模型的开放评测平台MedBench更新评测榜单,京东健康旗下“京医千询”大模型以综合得分92.4分的优异成绩位居榜单第一,彰显出该大模型在医疗智能化领域的实力。
测评图
作为上海AI实验室和上海市数字医学创新中心推出的权威评测平台,MedBench依托顶级医疗机构的专家经验和知识储备,致力于打造公平严谨的中文医疗大模型评测体系。目前,MedBench共设医学语言理解、医学语言生成、医学知识问答、复杂医学推理、医疗安全和伦理等5大测评维度,包含30万道中文医疗专业测评题目,可为中文医疗大模型提供客观科学的性能评测参考。
在评测中,京东健康“京医千询”大模型展现了其在处理复杂医疗场景时的高超能力。特别是在医学知识问答、病例分析与病历生成等核心任务上,该模型展示出超越常规模型的精准度与实用性。在针对特定医疗任务医学知识问答 、医学语言理解的专项评测中,“京医千询”医疗大模型更是拔得头筹,凸显了其在医疗专业领域的深厚积累。
据悉,“京医千询”医疗大模型发布于2023年7月,是行业内首个知识与数据相融合的医疗大模型,沉淀了超过亿级的覆盖线上、线下医患场景的高质量健康档案,并拥有海量的医药全域流通大数据。
“京医千询”大模型建立在京东言犀通用大模型基础之上,融合了通用数据、医疗专有数据、数智供应链原生数据,具有较高的产业属性和泛化能力,能快速完成在医疗健康领域各个场景的迁移和学习,从而实现产品和解决方案的全面AI化。正是基于此,京东健康将“京医千询”作为新一代医疗健康服务生态建设的“技术底座”,推动全行业解决方案和产品的智能化升级。
目前,京东健康皮肤医院基于大模型的AI辅诊准确率超过95%;京东健康与北京海淀区合作搭建的AI处方前置审核系统,已经在近百家基层医疗卫生机构落地使用,日均审核处方超过2万张;京东健康还基于“京医千询”大模型,面向执业医生推出了一系列解决方案,包括云诊室、诊后随访、专家联合会诊、临床科研、医生IP品牌孵化、“智能医生助手”工具等,优化了医生在线诊疗的效率和质量,提高了执业安全性。这些案例充分展示了“京医千询”医疗大模型在提高医疗服务质量和效率、改善患者就医体验、推动行业数字化转型方面的强大实力。
一直以来,京东健康依托技术积累、供应链及医疗服务的优势资源和能力,通过基于互联网化用户体验的产品、系统、解决方案的创新应用,助力医疗体系高质量发展。此次在MedBench测评榜中登顶,彰显了京东健康在行业垂直大模型“基础性”资源方面的显著优势。未来,京东健康将继续深耕数智医疗领域,不断推动大模型在医疗健康领域的多元场景应用,为优质医疗健康服务水平的提升带来更多助力。





